
Files
Contents
Introduction
For the hands-on portion of this workshop, we are going to use the TAGS tool, developed by
Martin Hawksey, to start an archive of tweets on a topic of our choice. TAGS functions as a Google Sheet plugin that allows you to interact with the Twitter Search API. Ideally, we will accomplish three things:
- Learn about the metadata embedded in a tweet, and consequently the kinds of questions we can ask of Twitter data.
- Formulate a preliminary research question, choose the search term(s) to capture the tweets relevant to that question, and set up a Twitter archive in a Google Sheet using TAGS.
- Time permitting, explore the included analytic tools, TAGSExplorer and TAGS Archive, to gather initial impressions and observations about the captured data.
Platform Limitations
The Twitter platform has limitations pertaining to representativeness. From the Pew Research Center’s Social Media Update:
- Twitter users are not representative of the general public.
- Younger Americans are more likely than older Americans to be on Twitter.
- Almost a third of Twitter users in the U.S. are college educated and middle- or upper-middle class.
Additionally, Twitter is not nearly as global as is often thought.
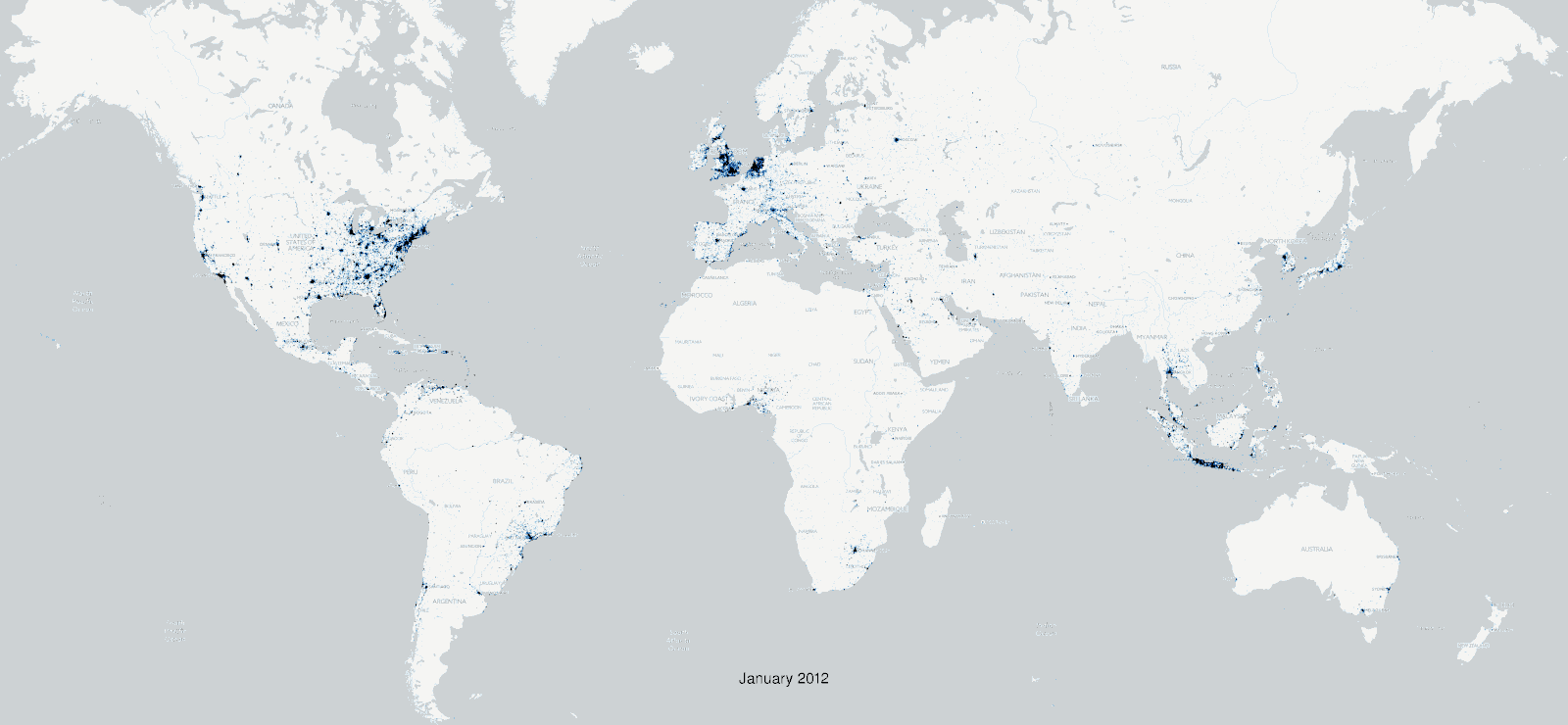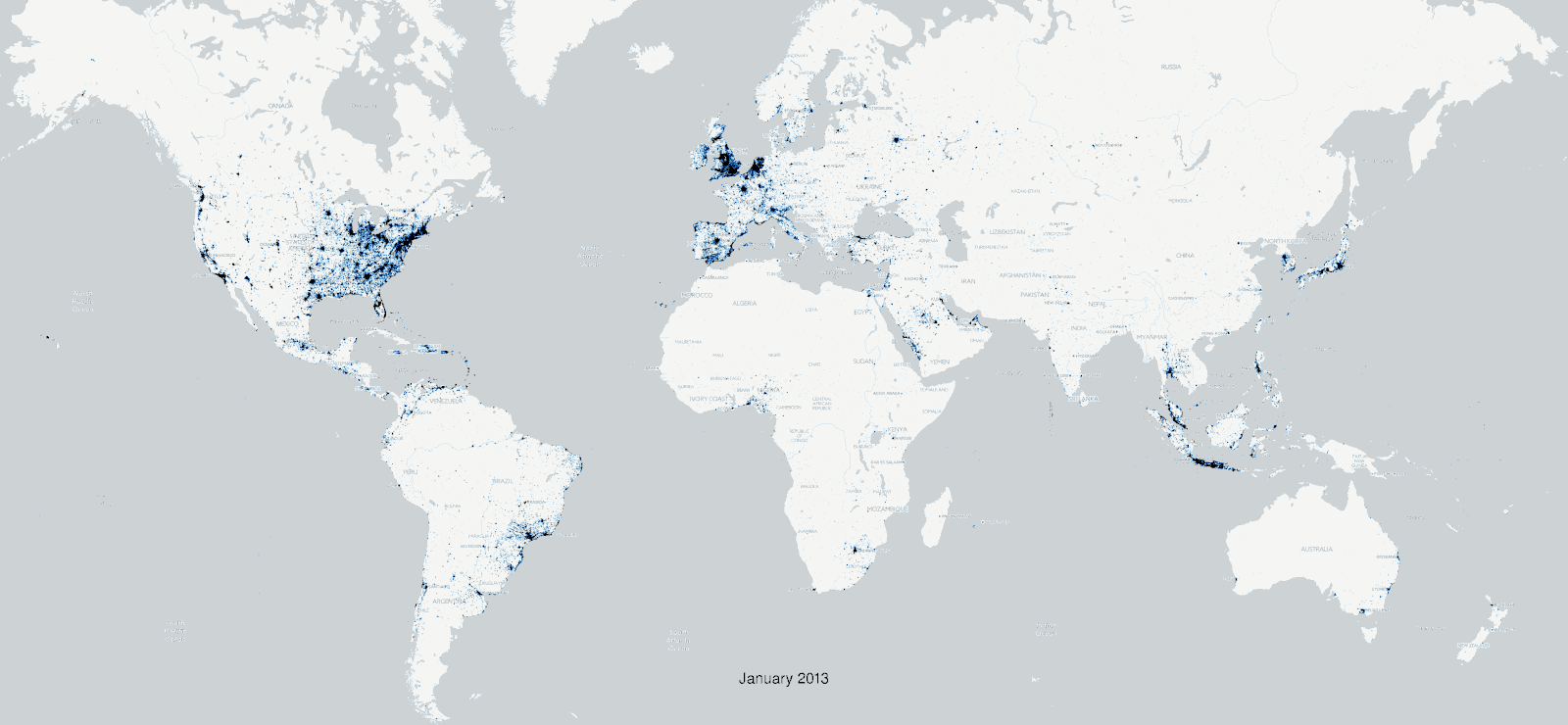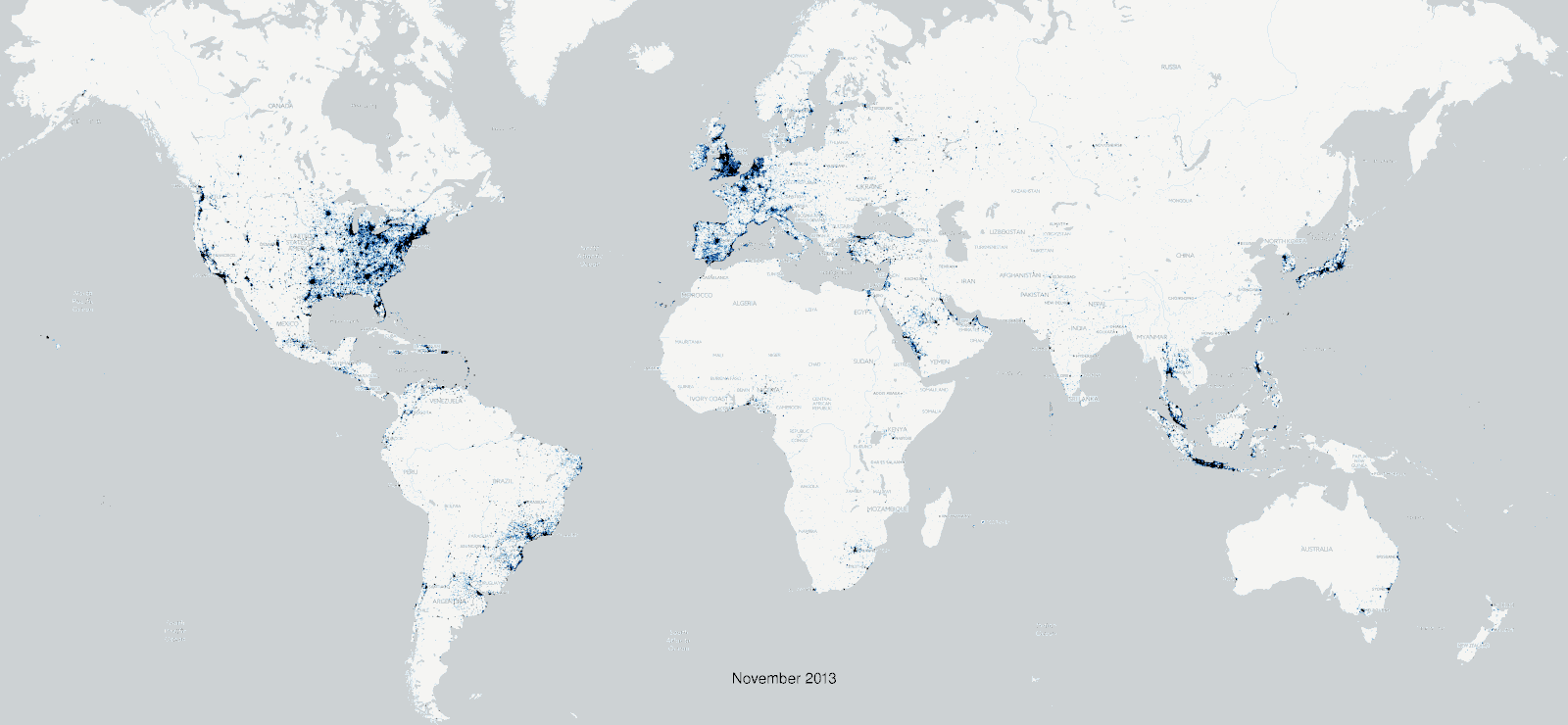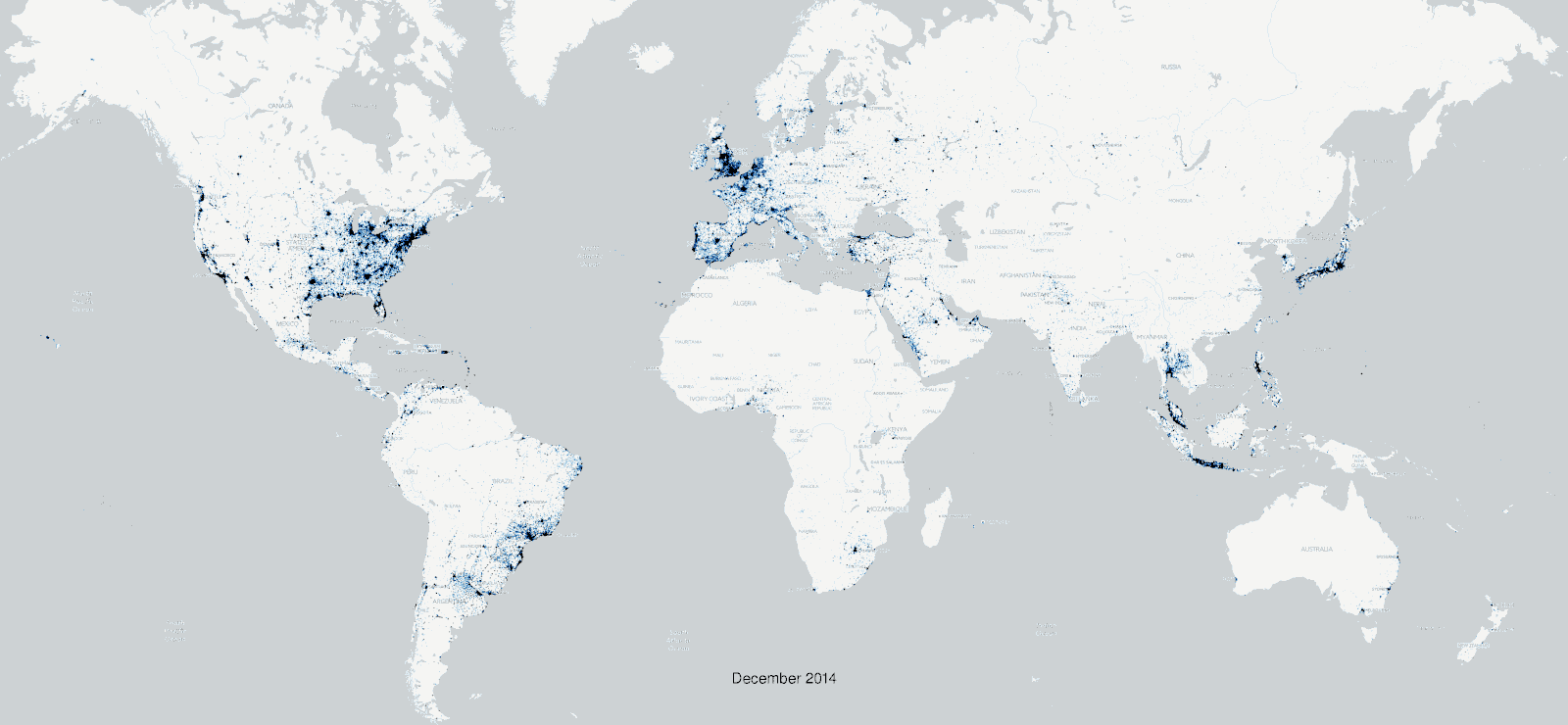
Furthermore, the Twitter Search API, which the TAGS tool relies upon, has important limitations to take into account. For starters, one cannot use it to retrieve tweets that are older than seven days. Consider also the rate limits that Twitter imposes on all of its APIs, which put a cap on how many times you can query the API in a given time window. The TAGS tool fortunately manages this issue for you behind the scenes. But if the phenomenon you hope to investigate is small (i.e. relatively few number of tweets), the rate limiting will slow down your data collection. Furthermore, none of the Twitter APIs support the creation of complete collections of tweets, and instead use a complex formula to arrive at a representative sample of tweets.
These limitations are important to keep in mind as you frame your research question. For instance, we probably can’t make generalizations about the population as a whole based on Twitter data. We can however measure short-term effects, and look for insights relating to the variables we’ve identified as being implicated in our research question. As a purely practical tip, it may make sense to investigate larger topics that generate lots of activity, rather than smaller topics where the resulting dataset may be a less faithful representation of the subject or phenomenon we want to investigate.
Tufekci provides a strong overview of the methodological considerations of using social media data for research in “Big Questions for Social Media Big Data: Representativeness, Validity and Other Methodological Pitfalls”.
Formulate a research question
Let’s spend a few minutes elaborating a research idea or question. Try out your search terms at
twitter.com/search to see how viable your topic might be. Your question doesn’t have to be detailed or complicated. For example, you could ask if the use of the hashtag #shitmystudentswrite is unethical… or if is it just good fun. Adding to that topic, are the tweets with the hashtag #shitacademicssay similar or dissimilar to those with #shitmystudentswrite? (In other words, do academics say things just as silly as their students?) In a different vein, what is this #catselfie hashtag about when cats haven’t got opposable thumbs? You can adjust and refine your topic, as well as any combination of hashtags, handles and free text you identify to capture that topic, based on your preliminary findings.
Create a search string to retrieve your data
Next, let’s identify the specific components of the search string you’ll use to explore your question. The search string can combine hashtags, handles, free text, and Boolean operators AND/OR, and is crafted to retrieve the data you’ll need to explore your topic. Try to select a topic that will produce a high number (500 – 1,000 or more) of tweets. Some suggestions follow.
- If history is your thing, and you’re curious about why and in whatcontexts Twitter users talk about the past, you might try #AskAnArchivist, #AskACurator, #OnThisDay OR #OTD, #history, or #twitterstorians.
- Suggestions for researching the academic community on Twitter mightinclude #shutupandwrite OR @SUWTNA OR #suwtna, or #phd.
- If you wanted to research writers on Twitter, academic or otherwise,you could try #amwriting.
- Some suggestions by genre: #books, #music, #poetry,#ScienceFiction OR #scifi, #painting.
- Sentiment, if that is your thing: #happy, #lol, #wow, #winning,#love, #thanks, and #smh (shake my head). Note that some of these will be ironic!
- Research on television fandom communities on Twitter might include#StrangerThings or #QueenSugar.
- Lastly, if you are motivated to investigate topics related to social and political issues, these are trending: Al Franken, elephant trophies, #NoMoore, and #DigitalMuslimBan. You will encounter a whole range of opinions, including offensive ones.
Please do check your search string in twitter.com/search to make sure there are enough tweets to match your query. You should look for tweets that are published at intervals of seconds, not minutes or days, in the live stream.
TAGS Tool setup (easy)
Open your browser of choice and navigate to https://tags.hawksey.info/. Click on Get TAGS. My recommendation is that we use TAGS 6.1. 1 You’ll also need to log into Google Drive on either a Gmail or Scarlet Mail account, and Twitter.
Clicking on the TAGS v6.1 button will take you to a Google Drive window in which you are asked to make a copy of TAGS v6.1.1. Do so. This creates a copy of the TAGS spreadsheet in your Google Drive. Rename it to something descriptive, i.e. My Test Archive.
In the navigation menu at the top of your screen, you should see a TAGS button. Go to TAGS > Setup Twitter Access. You’ll be guided through a series of steps that will grant the TAGS tool access to your Drive and to your Twitter account. Nota bene: be sure to enable pop-ups in your browser! In the pop-up window for granting access to Twitter, choose the Easy Setup button. If you’ve made it to this point successfully, skip ahead to Creating your Twitter archive in these instructions.
TAGS Tool setup (harder)
If you opt to use TAGS 6.1 with the custom keys option, follow the instructions under TAGS Tool setup (easy) until you reach the Twitter Authorization screen. At that point, click on the Custom Keys button. The steps in the next window will guide you to create a Twitter Developer account and register a Twitter application.
The TAGS tool will prompt you to register a new application at https://apps.twitter.com/app/new in order to get an API key and API secret. Fortunately, you only have to do this step once, after which you can create as many Twitter archives as desired and the TAGS tool will carry over your personal API key and API secret to the new spreadsheets.
Go ahead and reuse the information in the Description, Website and (important!) Callback URL fields, but please ensure that the Name field is unique to you. Click agree to the Developer Agreement at the bottom of the page. You may want to consult the Twitter Developer Policy at a later date. For now, the most important thing to recall is that you agree not to make the content you download publicly available online, unless you scrub it of all fields except the Tweet IDs and/or User IDs. At this point, if you haven’t yet given Twitter a mobile phone number, it will prompt you to supply this information before proceeding. Give it a real mobile number, because it will text you a confirmation code that you’ll need to enter. Next, you’ll get a screen saying that your application has been created. Hurray!! Click over to the Keys and Access Tokens menu. This screen is where you’ll get your API key and API secret. This information is personal and private, so treat it accordingly.
Next, enter the API key and API secret in the appropriate boxes of the pop-up Twitter Authorization window of the TAGS tool. Click next.
Hopefully you will make it through the daisy-chain of authorization windows in order to get your app set up. If not, we will try to trouble shoot it as a class. Hawksey has also created a very helpful setup video at https://youtu.be/Vm0kjAvH5HM.
Creating your Twitter archive
Now that those preliminaries are out of the way (phew!), we can concentrate on retrieving our Twitter data. Enter your search string in the box next to Enter term of the TAGS instructions. Then go to TAGS > Run now!
After allowing for the script to run for a moment or two, click over to the Archive tab of your spreadsheet. Do you see your tweets? Happy day! Have a look at the header row of your Archive tab. It should remind you of the Twitter JSON output we looked at earlier. Hawksey has mostly reused the Twitter field names, but not all of them are included in the default installation of the tool. If you are keen on adding some more, like retweet_count and favorite_count, this is what to do. Take a big breath, go to TAGS > Wipe Archive Sheet, and delete all those tweets you just collected. Then, go to the far right side of the spreadsheet and add a new column after the field entities_str. In the header row, add the fields you want. This is the list of what is available to add. I might suggest adding a column header with retweet_count, and a second with favorite_count. Then, go to TAGS > Run now!, and repopulate your spreadsheet. Scroll over to the right again. Did it capture your added Twitter fields? Excellent. You may also go to TAGS > Update archive every hour to keep collecting tweets automatically. The TAGS tool will continue issuing hourly calls to the Twitter Search API without you even needing to be logged into Google. To stop, just go to TAGS > Stop updating archive every hour.
Exploring and filtering your data
Go to TAGS > Add Summary Sheet and TAGS > Add Dashboard Sheet. Two new tabs should appear in your Google spreadsheet, with some interesting data about your archive, like Top Tweeters, Tweets with the most RTs (retweets), and time plots of Twitter activity. What can these views tell you about your data? Hawksey has created two interface tools to interact with the Twitter data you collect: TAGSExplorer and TAGS Archive. You can click on them from either your Summary or Dashboard tab. Note: You need to make your spreadsheet public on the web in order for this to work.
Each dot (also called a node) represents a Twitter user. The dot is sized by the number of connections (also called edges) it has with the other users in this dataset. So, the larger the node, the more edges it has (i.e. more tweets, mentions, replies). You can click on any node to get a window with the detail of those connections. TAGSExplorer will load only direct replies as the connections at first. But notice in the lower right-hand corner how you can add mentions and retweets as edges as well?
The edges will be differentiated by the type of line, e.g. solid gray for replies, dotted gray for mentions, and dotted blue for retweets. Either way, if you load the mentions and retweets as edges or not, you will probably encounter what is known in network analysis as the hairball problem. There are many tools and techniques for grooming the hairball, but for right now, you might as well appreciate the awesome unruliness of your data visualization. Can you make any sense of it? Who are the major actors in your Twitter network? Take time also to explore the Top Tweeters, Top Hashtags, and Top Conversationalists in your TAGSExplorer page. What can these basic visualizations tell you about your dataset?
If you want an easy way of drilling down to the level of individual tweets, you might be aided by the TAGS Archive interface, which will allow you to retrieve tweets from your data set by searching for any combination of user names, hashtags or free text. What phenomenon observed in the TAGSExplorer interface might prompt you to look at individual tweets?
Where to Next?
The TAGS tool is among the easiest applications for collecting Twitter data, in that it doesn’t require familiarity with programming languages or the command line, and it does a good job of automating data collection, API limitations notwithstanding. However, if you are interested in more complex data collection and filtering, reusing another researcher’s Twitter dataset, i.e. from the DocNow Catalog, or in using different social media APIs, have a look at slides 22-25 in the workshop slidedeck for additional tools.
If you’d like help setting up and exploring these tools, please feel free to contact me for a research consultation.
Francesca Giannetti
Digital Humanities Librarian
francesca.giannetti AT rutgers.edu
Lastly, a reminder that there’s a companion workshop, “Manipulating and Analyzing Social Media Data in R”, next November 21 at 1-2:30 pm in Alexander Library, room 413.
- What’s the difference between “easy setup” and “custom keys”? Hawksey introduced a simplification in version 6.1 that eliminates the necessity of creating a Twitter Developer account and registering an application. If you use TAGS 6.1 (recommended), and opt for easy setup, what that means is that you are using the developer’s Twitter API key and secret. So if Hawksey were to delete his account, or exceed the maximum number of users, your TAGS archive would not function. To exercise greater control, you might want to follow the instructions for version 6.1 with the custom keys option, and use your own API key and secret. I’ve included those instructions here as a failsafe. ?
1 Comment
Comments are closed.